揭秘Unity的黑盒世界,,“ShaderLab”底層原理淺談
在閱讀本文之前我們首先需要弄清楚什么是 ShaderLab?
ShaderLab是由Unity發(fā)明或者說是由Unity首創(chuàng)的一種語言體系,,用來幫助大家做跨平臺Shading開發(fā),。它里面除了語言規(guī)則之外,還有很多其他的東西,。我們一個個來看,。
我們先來看看ShaderLab Text(就是它的文本)。
我們大家知道,無論是寫代碼,,還是寫shading,,實際上我們寫的都是一堆文本。雖然在IDE 里看起來“花里胡哨”的,,但是對計算機來講就是文本,。大家能看到,這就是我們非常熟悉的Unity的Shader,,這個東西叫ShaderLab文本,,是根據(jù)Unity定義的語法規(guī)則來寫的。

我們可以看到,,在基礎(chǔ)文本里面會包含一些塊,比如說Shader的名字,,在Subshader里面也有它自己的屬性,,比如Tag、LOD等等,。在Subshader下面還有一個個Pass,,在Pass里面我們還可以定義不同的pragma、Vertex,、Fragment,,而其中的每個都對應(yīng)著不同的代碼塊。
這是ShaderLab第一個組成的部分,,我們稱之為ShaderLab文本,。
但光有文本是不行的,就如同你寫C++,,如果只是寫了一堆CPP文件,,依然是無法被計算機認(rèn)可并執(zhí)行的。中間需要有翻譯的過程,,這就是Shader Compiler的過程,。如果大家在 Windows或者是Mac上有留意過的話,就會發(fā)現(xiàn),,打開Unity之后再打開任務(wù)管理器,,或者在Mac上打開active monitor,你都會看到一個叫Unity shader Compiler的東西,。如果是早期的Unity版本,,你看到的就可能是cgbatch。
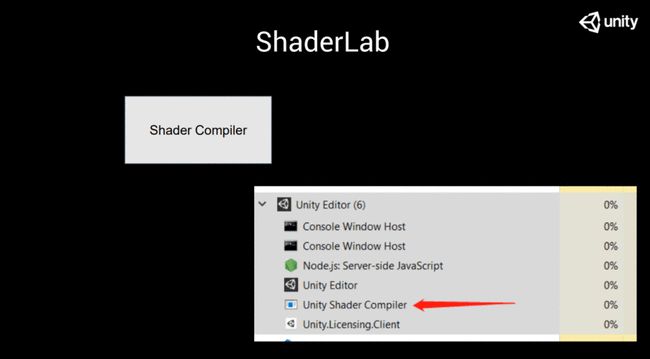
這個東西是干什么的呢,?實際上它類似一種服務(wù),,是Unity在后臺提供的一種服務(wù),用來幫助我們?nèi)グ褜懞玫腟haderLab語言翻譯為目標(biāo)機器能夠認(rèn)可并執(zhí)行的語言(我們會在下文中講解大概是怎么翻譯的)。
這是第二個組成模塊,。
第三個是一個體系,,我們稱之為ShaderLab Asset。我們寫的ShaderLab大部分是不會進(jìn)入到最終的運行環(huán)境中去的,,需要經(jīng)過二次加工,。ShaderLab里面有很多東西都是不能直接使用的,需要進(jìn)行翻譯,。而加工之后的東西,,我們叫它Asset(資產(chǎn)),這個Asset比較常見的是這兩個地方,。

第一個地方,,是我們打Assetbundle,這是大家最常見的,,我們把shader 打成一個包,,放到 bundle里。
還有一個就是在我們打出來包的Resources下面,,會有l(wèi)evel或者是 SharedAssets 這樣的包,,其實和Assetbundle的文件結(jié)構(gòu)是很類似的,比如說場景里面直接引用的一些東西,,大家既愛又恨的Always include Shader也在這里面,。
這是兩個Asset比較常見的地方。
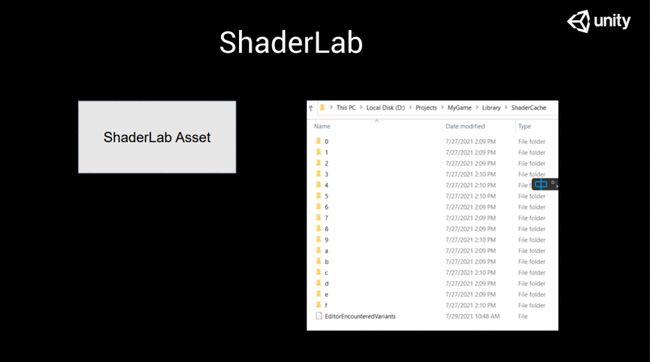
但是有一個地方,,大家不經(jīng)常會用到,。當(dāng)我們在 library 文件夾里打開一個工程,就會看到一個叫 ShaderCache 的文件,。我們在做預(yù)處理之后的中間產(chǎn)物,,都會放到ShaderCache里面。
我們都知道Unity特別喜歡使用GUID做索引的,,這個看起來和我們的library里面的data的東西很相似,,也是一堆以數(shù)字或字母開頭的文件夾,然而我們現(xiàn)在看到的這個也是ID但不是GUID,。如果大家曾經(jīng)拆過Unity AssetBundle,,你會看到你寫的代碼。
你會經(jīng)??吹秸麄€從CGPROGRAM到ENDCG,,在你的Asset里看不到了,變成了一個名字叫 GPU program IDXXX的文件,,用一個ID索引了這一整段,。在里面我們可以很簡單地認(rèn)為里面存的就是大家寫的CG program中間的東西,,當(dāng)然不是直接存進(jìn)去的,是經(jīng)過了一系列的加工,。這是我們存儲幾個shaderAsset的地方,。
最后還有一個大家會經(jīng)常遇到但是往往被忽略掉的事情——ShaderLab是有Runtime的。既然是一種有語法結(jié)構(gòu)的語言,,會包含很多的信息,,Runtime能不能把這些信息利用起來就變得很重要。不然的話寫了半天,,打上Asset也沒人用,,就白白浪費掉了。
這個東西經(jīng)常在哪兒見到呢,?答案就是在Memory里面,,如果你去使用一個Sample,你會在ShaderLab里面看到它,。
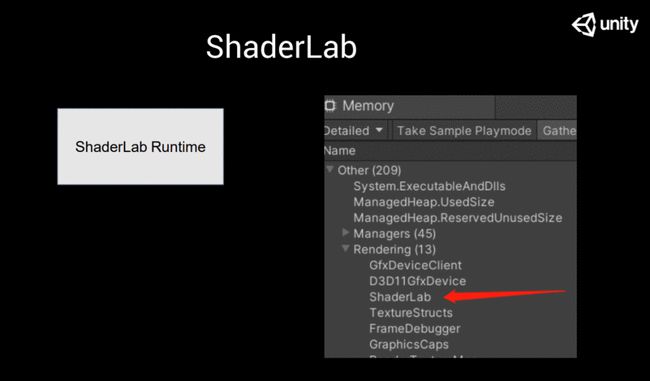
這也是大家問題最集中的地方,,為什么我ShaderLab這么大,到底是哪個Shader大,?其實不是Shader大,而最有可能的是ShaderLab 整體很大,。
所以整個Unity的ShaderLab大致分為四塊,,分別是由ShaderLab Text、shaderLab Compiler,、shaderLab Asset以及shaderLab Runtime四個部分組合而成的,。

我們了解了 ShaderLab 之后,再簡單地看一下 ShaderLab 的工作流,。
首先,,當(dāng)我們?nèi)プ?Shader 的時候,第一步就是去寫ShaderLab的Text,,寫完了之后干什么呢,?寫完之后你會發(fā)現(xiàn),當(dāng)你回到Unity的時候,,Unity會開始有一個編譯的過程,,如果你第一次導(dǎo)入了很多的Shader,這個時候ShaderCompiler就開始工作了,。
Unity的Shader 不是一次性編譯到一個平臺上的,。
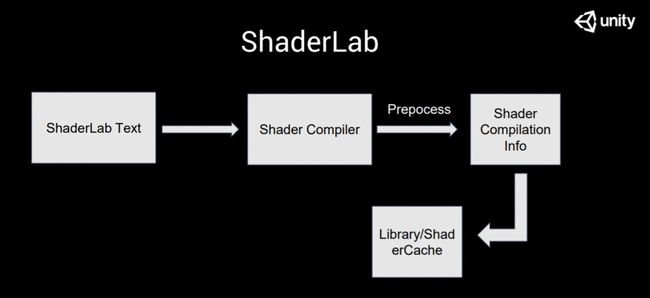
那么這個名為ShaderCache的東西,它是在什么時候產(chǎn)生的呢,?其實在 shader被import進(jìn)Unity系統(tǒng)的時候,,Unity 會把原始的shader文本發(fā)給shaderCompiler去做一次預(yù)處理,,預(yù)處理的結(jié)果并不是針對某一個平臺最終的文本結(jié)構(gòu),這個時候編譯出來的東西叫shader compilation info,,是一個中間狀態(tài)的一個信息集,,這個信息集里面包含了很多重要的東西。以下是其中比較重要的幾點:
第一,,你的變體,。我們知道 Unity 引入了 multi compile 和 shader feature 之后,通過一次編碼就可以產(chǎn)生大量不同的 Shader,。第一次我們?nèi)ヌ幚沓鲎凅w的概念,,是在我們做 Preprocess 的時候出現(xiàn)的。經(jīng)過 Preprocess 第一次的處理,,在 shader compilation info 里面,,就已經(jīng)把各個變體分開了。
當(dāng)我們?nèi)グ?shader compilation info 編譯出來之后,,會把相關(guān)的信息序列化,,并且寫到我們 ShaderCache 里面,這就是大家所看到的 ShaderCache,。這個ShaderCache的信息會被用于我們后面的一些加速編譯,,不需要每次進(jìn)入Unity都重新走一遍過程。當(dāng)你的shader比較大,,變體比較多的時候,,Preprocess的過程是相對比較慢的。Preprocess的過程,,如果我們更細(xì)化地說,,實際上做了以下幾件事情。
第一個是做語法分析,,比如說我們解析語法數(shù),,就會生成詞法解析器和語法解析器。我們先去做了一次語法解析和詞法解析,,當(dāng)然在這個過程中Unity就會去檢查大家的shader寫得有沒有問題,,如果有報錯,這個階段就完成了,。
當(dāng)我們解析完了之后,,Unity會把每一種不同的語言,從shader的文本中對應(yīng)的部分切割出來,。切割出來之后,,再用對應(yīng)的語言的Preprocess compile去做一遍對應(yīng)這個語言的解析檢查。通過這幾次檢查之后,,最終我們會得到完整的compilation info,,再把它寫到ShaderCache 里面,。
如果大家在去做一個Shader的時候,發(fā)現(xiàn)寫完的這個Shader好像不太對,,或者有點問題,,你感覺沒有進(jìn)行重新編譯,最簡單的方法就是把ShaderCache刪掉,,然后再強行導(dǎo)入一次,,重新編譯一次,這時候問題就迎刃而解了,。
我們把它編出來,,放到ShaderCache 里之后,這個時候只是Unity editor拿到了Compile 這個東西,,但并不能用于渲染,,也不能打到最終的包里。它只是Unity所使用的中間狀態(tài),,如果是編譯的話,,大概就類似于IR的東西。
我們?nèi)绾伟阉罱K編譯成可運行的版本呢,?
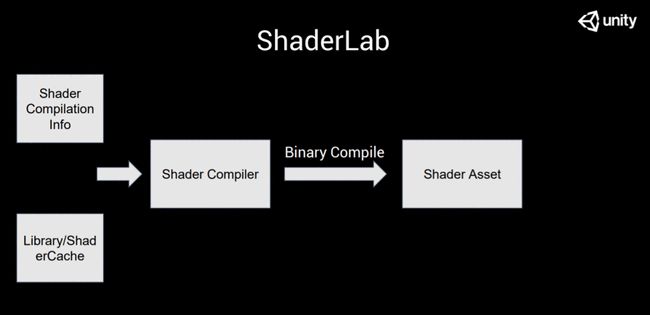
我們可以從shader Compilation info,,或者是ShaderCache里面找到相應(yīng)的文件。這取決于你有沒有,,如果有的話,,就能從shadercache里找到;如果沒有的話,,就會走一遍Prepocess的過程,,再重新產(chǎn)生shader Compilation info,。
拿到之后,,我們會把這個東西再送到shader Compiler里面,再做一些其他的事情,。這個 shader Compiler里面包含了很多不同的服務(wù),,剛才是Preprocess,這次我們要做的就是Binary Compile,。這個事情會在以下幾種情況下發(fā)生,。
第一,我們現(xiàn)在啟動了Unity,。我們把資源都導(dǎo)入了,,點擊play。點的時候,,Unity 會做一件叫Unity Editor warmup all shader的事情(當(dāng)然在第一次導(dǎo)入的時候,,Unity 也會做),。這就是為什么2020年之前的版本,大家在點開始的時候,,會經(jīng)常感覺到卡半天,。實際上,“卡”的過程會把你內(nèi)存里面,,或者是資源里面所有shader的變體都warmup,。但是真機上不會卡。
大家在去做一些性能檢查,,包括去研究原理的時候你會驚訝地發(fā)現(xiàn),,Unity 實際上是兩個版本,運行時和編輯期是兩套完全不同的東西,。所以我們在做性能分析,,或者是內(nèi)存、CPU,、GPU 分析的時候,,不要在編輯器里面做。編輯器的設(shè)計目的是為了幫助大家以最流暢的速度去編輯,,所以有很多的東西,,不會去考慮運行時資源環(huán)境的占用,比如CPU或是內(nèi)存的占用,。Unity會默認(rèn)認(rèn)為你的電腦非常棒,,內(nèi)存不會爆,CPU不會卡,,所以它可以盡情地?fù)]霍這些資源,,盡量保證大家整體的編輯體驗是好的。但是在運行時,,Unity會考慮實際的運行環(huán)境,。比如手機和PC上的策略會有一些差異。
在這個地方我們進(jìn)行 Binary Compile,。
第二種情況,,是真正開始打包了,比如說我們要給安卓打一個AssetBundle,,或者發(fā)一個安卓的APK,,這時候也會觸發(fā)這個過程??傊|發(fā)這個過程的必要前提是我的目標(biāo)平臺是明確的,,我知道要把中間的東西最終要翻譯成什么。BinaryCompile 的過程其實是一個非常神奇的過程,,Unity 實際上也不是直接把大家寫的,,比如說CG就直接翻譯到目標(biāo)平臺上,,這個工作量其實是很大的。
關(guān)于Unity的目標(biāo)平臺就非常多了,,比如說大家常見的手機平臺上有很多的API,,加上主機平臺,他們都有自己整套的語言規(guī)范,。
大家可以腦補一下如果我們要是強行翻會怎樣,。這是一個乘的關(guān)系,左邊4個,,假如說右邊是10個不同的平臺,,那就是40個,要寫40套不同的代碼,,代碼的路徑就非常的繚亂,。其一代碼維護(hù)難度很大,其二是也很難寫,。
Unity使用了第三方技術(shù),,名為HLSLCC,CC的意思是交叉編譯器,,大家可以搜到,。這個最終幫助Unity做出了一些優(yōu)化和改變,和Unity使用的版本不是完全一樣的(大家不要把網(wǎng)上的內(nèi)容改一下直接替進(jìn)來,,這樣行不通),。
Unity 實際上做了這樣的工作:Unity會先把前端的一些語言,盡量地翻譯到DX那個級別上去,,通過DX的編輯器進(jìn)行編輯,,編輯完了之后,后端再走到HLSLCC,,再向目標(biāo)平臺去輸出,,相當(dāng)于是一個兩步編譯的過程。所以整體的難度降低了很多,,大部分的工作是由HLSLCC來做的,。
這個編譯過程也會導(dǎo)致一個問題,,比如DX里面沒有,,翻譯不過去,中間要經(jīng)過一步,,其實就相當(dāng)于過路費要交,,但是過路的時候沒有這個東西。因此Unity在2020以后的版本,,最早的時候是用的DXBC,,而現(xiàn)在用的則是DXRL,,Unity也是基礎(chǔ)于DX的編譯器進(jìn)行了自己的擴展,以便盡可能地去支持一些新特性,。
 打印本文
打印本文 關(guān)閉窗口
關(guān)閉窗口